Western Rail Approach to Heathrow
As part of the Network Rail Railway Upgrade Plan the Department For Transport were developing a plan to build a route to Heathrow airport from the west, avoiding central London.
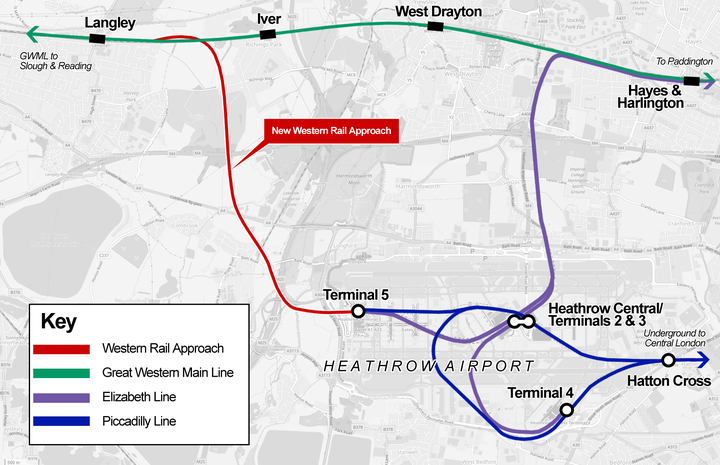
The Western Rail Link to Heathrow would leave the Main Line between Langley and Iver. It would then descend underneath the main railway line into a cutting before entering a 5km tunnel. The tunnel would pass under Richings Park and Colnbrook and then merge with existing rail lines underground at Heathrow Terminal 5.
The proposed rail link would:
- Reduce rail journey times between Reading and Heathrow by delivering a new, faster, frequent, more reliable direct train service to Heathrow with four trains per hour in each direction. All trains would call at Reading and Slough and alternate trains at Twyford and Maidenhead. Journey times could be as short as 26 minutes from Reading and 6 to 7 minutes from Slough.
- Significantly improve rail connectivity to Heathrow from the Thames Valley, South Coast, South West, South Wales and West Midlands.
- Provide an alternative form of transport for passengers and the large number of people who work at the airport who are currently travelling by road.
- Ease congestion on roads, including the M4, M3 and M25 resulting in lower CO2 emissions equivalent to approximately 30 million road miles per year.
- Generate economic growth and new jobs across the Thames Valley and surrounding areas.
- Reduce passenger congestion at London Paddington.
As such there was a significant amount of analysis required to determine the value for money that such a route would provide. As lead data scientist for the project my role was to take large journey time and demand matrices for each proposed build case and either refactor them for GIS analysis or develop algorithms to determine the demand value across different passenger sectors.
Traditionally this kind of demand modelling has been a slow process, using only a subset of available data. This is because the data inolved is far too big for traditional spreadsheet modelling. However replacing the spreadsheet component with algorithms developed in R allowed us to cycle through multiple business case model analyses across several years using the full datasets of each (in excess of 16 million data points per input type with 3 or 4 types per input set) using an automated method. This allowed the results to be produced, processed quickly and maintain strong audit trails and verifiability.
David Rickmann
Data Scientist
My research interests include transport as a system, data science and asteroid mining.